DMR 入门
Docker Model Runner (DMR) 允许您使用 Docker 在本地运行和管理 AI 模型。本页将向您展示如何启用 DMR、拉取并运行模型、配置模型设置以及发布自定义模型。
启用 Docker Model Runner
您可以使用 Docker Desktop 或 Docker Engine 启用 DMR。请根据您的设置按照以下说明操作。
Docker Desktop
- 在设置视图中,前往 AI 选项卡。
- 选择 Enable Docker Model Runner 设置。
- 如果您在 Windows 上使用受支持的 NVIDIA GPU,您还会看到并可以选择 Enable GPU-backed inference。
- 可选:若要启用 TCP 支持,请选择 Enable host-side TCP support。
- 在 Port 字段中,输入您想要使用的端口。
- 如果您从本地前端 Web 应用与 Model Runner 交互,请在 CORS Allows Origins 中选择 Model Runner 应接受其请求的源(Origin)。源是您的 Web 应用运行的 URL,例如
http://localhost:3131。
您现在可以在 CLI 中使用 docker model 命令,并在 Docker Desktop Dashboard 的 Models 选项卡中查看本地模型并与之交互。
Important对于 Docker Desktop 4.45 及更早版本,此设置位于 Beta features 选项卡下。
Docker Engine
-
确保您已安装 Docker Engine。
-
Docker Model Runner 以软件包形式提供。要安装它,请运行:
$ sudo apt-get update $ sudo apt-get install docker-model-plugin$ sudo dnf update $ sudo dnf install docker-model-plugin -
测试安装:
$ docker model version $ docker model run ai/smollm2
Note对于 Docker Engine,TCP 支持默认在端口
12434上启用。
在 Docker Engine 中更新 DMR
要在 Docker Engine 中更新 Docker Model Runner,请使用
docker model uninstall-runner 将其卸载,然后重新安装:
docker model uninstall-runner --images && docker model install-runnerNote使用上述命令会保留本地模型。若要在升级期间删除模型,请在
uninstall-runner命令中添加--models选项。
拉取模型
模型会缓存在本地。
Note当您使用 Docker CLI 时,也可以直接从 HuggingFace 拉取模型。
- 选择 Models 并选择 Docker Hub 选项卡。
- 找到您需要的模型并选择 Pull。
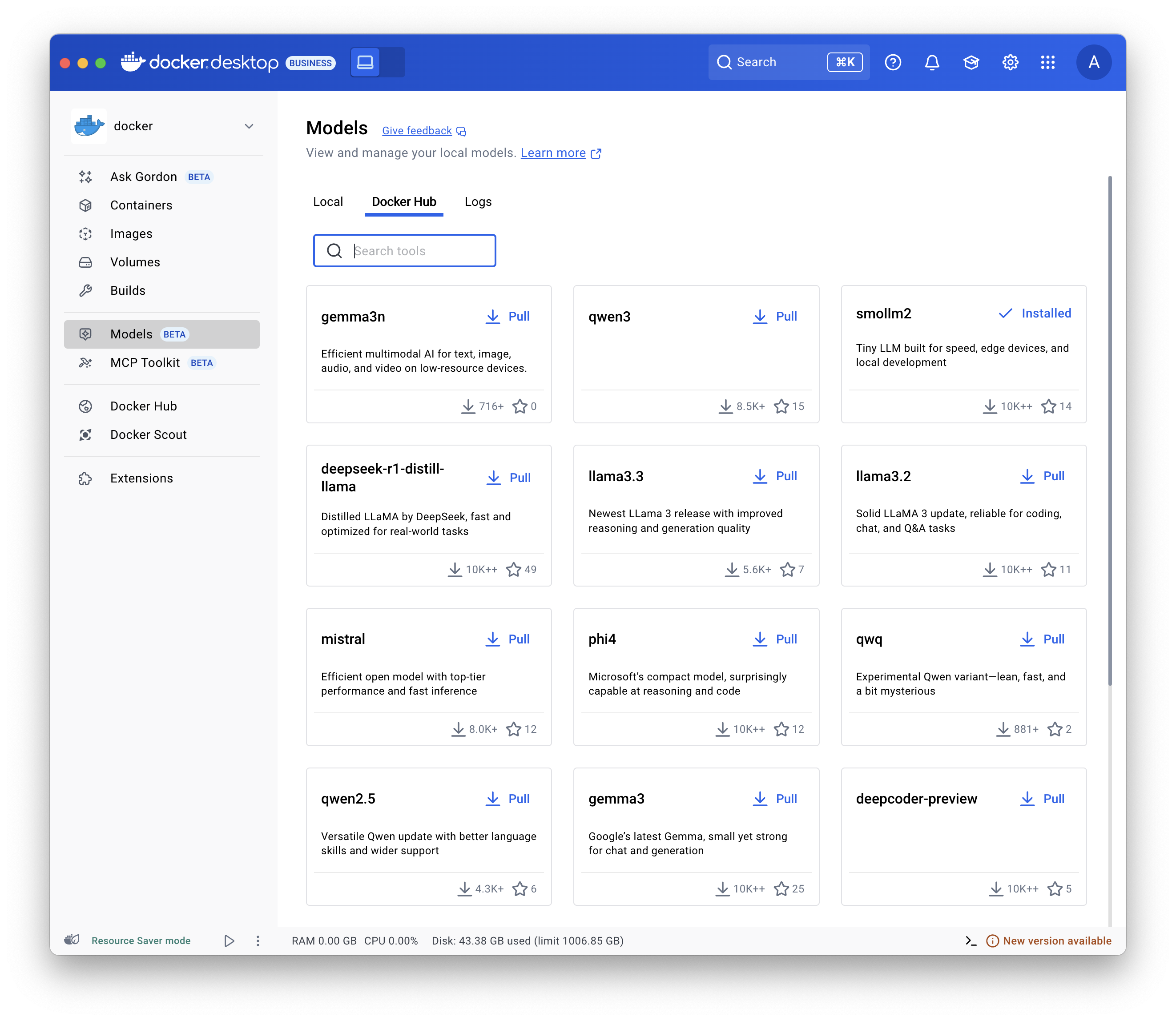
使用
docker model pull 命令。例如:
docker model pull ai/smollm2:360M-Q4_K_Mdocker model pull hf.co/bartowski/Llama-3.2-1B-Instruct-GGUF运行模型
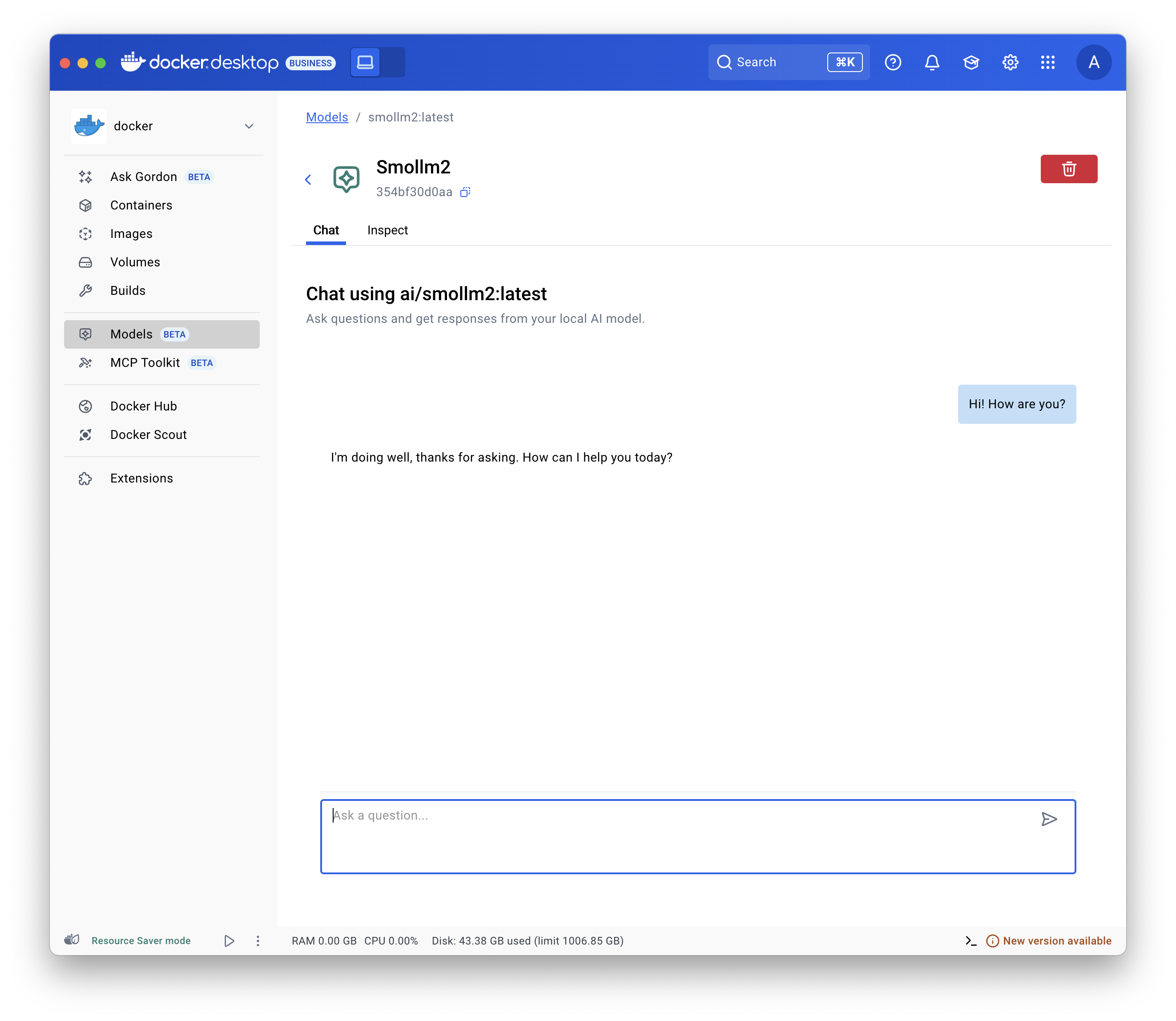
- 选择 Models 并选择 Local 选项卡。
- 选择播放按钮。交互式聊天界面将打开。
配置模型
您可以使用 Docker Compose 配置模型,例如其最大 token 限制等。请参阅 Models and Compose - 模型配置选项。
发布模型
Note这适用于任何支持 OCI Artifact 的容器注册表,不仅限于 Docker Hub。
您可以为现有模型标记新名称,并将其发布到不同的命名空间和仓库下:
# 为拉取的模型标记新名称
$ docker model tag ai/smollm2 myorg/smollm2
# 将其推送到 Docker Hub
$ docker model push myorg/smollm2更多详情请参阅
docker model tag 和
docker model push 命令文档。
您还可以将 GGUF 格式的模型文件打包为 OCI Artifact 并发布到 Docker Hub。
# 下载 GGUF 格式的模型文件,例如从 HuggingFace 下载
$ curl -L -o model.gguf https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF/resolve/main/mistral-7b-v0.1.Q4_K_M.gguf
# 将其打包为 OCI Artifact 并推送到 Docker Hub
$ docker model package --gguf "$(pwd)/model.gguf" --push myorg/mistral-7b-v0.1:Q4_K_M更多详情请参阅
docker model package 命令文档。
故障排除
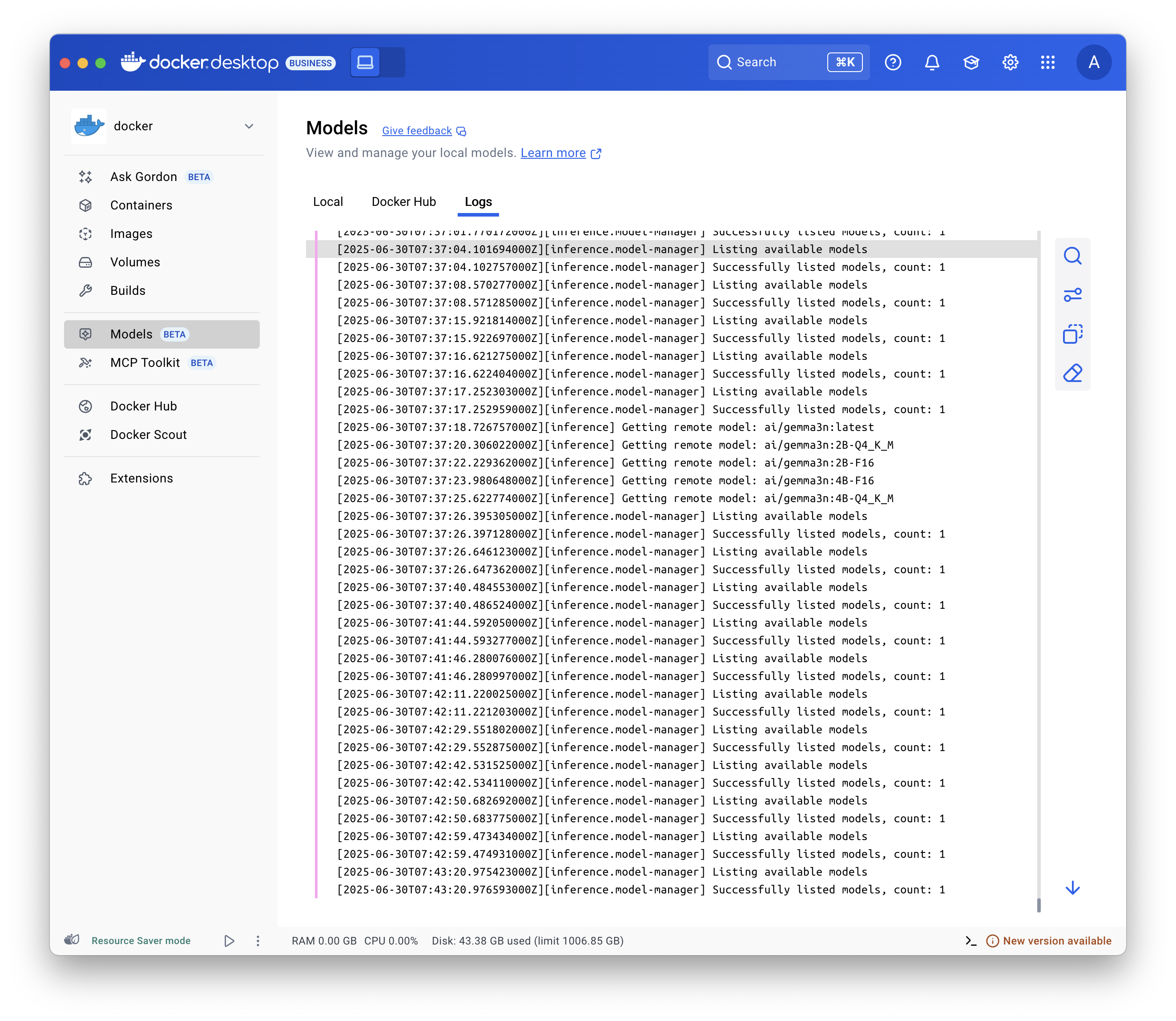
显示日志
要排除故障,请显示日志:
选择 Models 并选择 Logs 选项卡。
检查请求和响应
检查请求和响应有助于您诊断与模型相关的问题。例如,您可以评估上下文使用情况以验证是否保持在模型的上下文窗口内,或者显示请求的完整正文,以便在使用框架开发时控制传递给模型的参数。
在 Docker Desktop 中,要检查每个模型的请求和响应:
- 选择 Models 并选择 Requests 选项卡。此视图显示指向所有模型的所有请求:
- 请求发送的时间。
- 模型名称和版本。
- 提示词/请求。
- 上下文使用情况。
- 生成响应所花费的时间。
- 选择其中一个请求以显示更多详情:
- 在 Overview 选项卡中,查看 token 使用情况、响应元数据和生成速度,以及实际的提示词和响应。
- 在 Request 和 Response 选项卡中,查看请求和响应的完整 JSON 负载。
Note当您选择特定模型然后选择 Requests 选项卡时,也可以显示该模型的请求。
相关页面
- API 参考 - OpenAI 和 Ollama 兼容的 API 文档
- 配置选项 - 上下文大小和运行时参数
- 推理引擎 - llama.cpp 和 vLLM 详情
- IDE 集成 - 连接 Cline、Continue、Cursor 等
- Open WebUI 集成 - 设置 Web 聊天界面
- 模型与 Compose - 在 Compose 应用中使用模型
- Docker Model Runner CLI 参考 - 完整的 CLI 文档