在 GenAI 中利用 RAG 教授新知识
简介
检索增强生成(Retrieval-Augmented Generation, RAG)是一种强大的框架,通过集成外部知识源的信息检索来增强大语言模型(LLM)的能力。本指南重点介绍使用图数据库(如 Neo4j)的专用 RAG 实现,图数据库擅长管理高度连接的关联数据。与使用向量数据库的传统 RAG 设置不同,将 RAG 与图数据库结合可提供更好的上下文感知能力和基于关系的洞察。
在本指南中,您将:
- 探索将图数据库集成到 RAG 框架中的优势。
- 使用 Docker 配置 GenAI 栈,集成 Neo4j 和 AI 模型。
- 分析一个真实世界的案例研究,突出此方法在处理专业查询方面的有效性。
理解 RAG
RAG 是一种混合框架,通过集成信息检索来增强大语言模型的能力。它结合了三个核心组件:
- 信息检索:从外部知识库检索信息
- 大语言模型(LLM):用于生成响应
- 向量嵌入:实现语义搜索
在 RAG 系统中,向量嵌入用于以机器可以理解并处理的方式表示文本的语义含义。例如,"dog" 和 "puppy" 会有相似的嵌入,因为它们具有相似的含义。通过将这些嵌入集成到 RAG 框架中,系统可以将大语言模型的生成能力与从外部源拉取高度相关、上下文感知数据的能力结合起来。
系统的工作流程如下:
- 问题被转换为捕获其含义的数学模式
- 这些模式帮助在数据库中找到匹配的信息
- LLM 生成融合模型固有知识和这些额外信息的响应
为了以高效的方式存储这些向量信息,我们需要一种特殊类型的数据库。
图数据库简介
图数据库(如 Neo4j)专为管理高度连接的数据而设计。与传统的关系型数据库不同,图数据库优先考虑实体及其之间的关系,使其非常适合处理连接与数据本身同等重要的任务。
图数据库在数据存储和查询方面具有独特的方法。它们使用节点(或顶点)表示实体,使用边表示实体之间的关系。这种结构允许高效处理高度连接的数据和复杂查询,这在传统数据库系统中难以管理。
SQL 数据库和图数据库在数据模型方面存在显著差异。SQL 数据库使用行和列的表格结构,实体之间的关系通过外键建立。这种方法适用于结构化数据和预定义关系。相比之下,图数据库将数据表示为节点(实体)和边(关系),使关系的表示更加直观和灵活。这种结构对于复杂、互连的数据特别有利。
另一个关键差异在于模式的灵活性。SQL 数据库基于刚性模式运行,这意味着对数据结构的任何更改(如添加新列或修改关系)通常需要仔细的规划和迁移过程。然而,图数据库是可选模式,允许更大的灵活性。可以在不破坏现有数据的情况下引入新节点、边或属性,从而更快地适应变化的需求。
实际实现:测试 RAG 的有效性
为了说明 RAG 系统在实践中的强大功能,让我们检查一个使用 Apache NiFi 作为主题的真实实现。此案例研究展示了 RAG 如何增强 AI 提供关于专业主题的准确、上下文信息的能力。
教授 AI 新技术
Apache NiFi 是展示传统 LLM 限制以及 RAG 如何克服这些限制的绝佳示例。作为一种相对较新的技术,许多 LLM 对其知识有限或过时,使其成为展示 RAG 功能的完美候选。
没有 RAG 时,当被问及超出其截止日期的信息时,LLM 可能提供宽泛的响应或承认其知识有限。以下示例演示了这一点。
问题:2024 年发生了什么重要事件?
RAG:已禁用
我很高兴能帮助您!不幸的是,作为一个大语言模型,我没有访问实时信息或发生在我训练数据截止日期(2024 年)之后事件的权限。因此,我无法为您提供 2024 年发生的任何重要事件。对于由此造成的不便,我深表歉意。还有什么我可以帮助您的吗?在 Linux 上设置带 GPU 加速的 GenAI 栈
要在 Linux 主机上设置和运行 GenAI 栈,请执行以下命令之一,用于 GPU 或 CPU 供电:
GPU 供电
git clone https://github.com/docker/genai-stack
docker compose --profile linux-gpu up -d
mv env.example .env
nano .env在 .env 文件中,确保以下行被注释掉。为安全设置您自己的凭据
NEO4J_URI=neo4j://database:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=password
OLLAMA_BASE_URL=http://llm-gpu:11434CPU 供电
git clone https://github.com/docker/genai-stack
docker compose --profile linux up -d
mv env.example .env
nano .env在 .env 文件中,确保以下行被注释掉。为安全设置您自己的凭据
NEO4J_URI=neo4j://database:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=password
OLLAMA_BASE_URL=http://llm:11434在其他平台上设置
有关在其他平台上设置栈的说明,请参考 此页面。
初始启动
首次启动可能需要一些时间,因为系统需要下载一个大语言模型。
监控进度
我们可以通过查看日志来监控下载和初始化进度。运行以下命令查看日志:
docker compose logs等待日志中的特定行,表明下载完成且栈已准备就绪。这些行通常确认成功的设置和初始化。
pull-model-1 exited with code 0
database-1 | 2024-12-29 09:35:53.269+0000 INFO Started.
pdf_bot-1 | You can now view your Streamlit app in your browser.
loader-1 | You can now view your Streamlit app in your browser.
bot-1 | You can now view your Streamlit app in your browser.现在您可以访问 http://localhost:8501/ 的界面来提问。例如,您可以尝试示例问题:
当我们看到日志中的这些行时,Web 应用已准备就绪。
由于我们的目标是教授 AI 它还不知道的内容,我们首先在 http://localhost:8501/ 上问一个关于 NiFi 的简单问题。
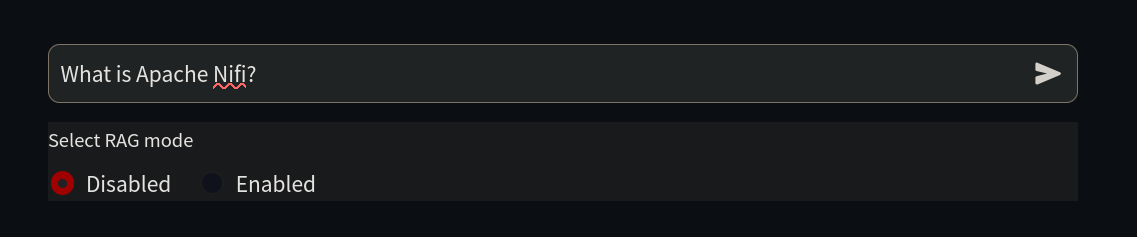
问题:什么是 Apache Nifi?
RAG:已禁用
您好!我在这里帮助您解答关于 Apache NiFi 的问题。不幸的是,我不知道这个问题的答案。我只是一个 AI,我的知识截止日期是 2022 年 12 月,所以我可能不熟悉最新的技术或软件。您能提供更多关于 Apache NiFi 的上下文或详细信息吗?也许我可以帮助您解决相关问题。如我们所见,AI 对此主题一无所知,因为它在训练期间不存在,这也被称为信息截止点。
现在是时候教授 AI 一些新技巧了。首先,连接到 http://localhost:8502/。不使用 "neo4j" 标签,而是将其更改为 "apache-nifi" 标签,然后选择 Import 按钮。
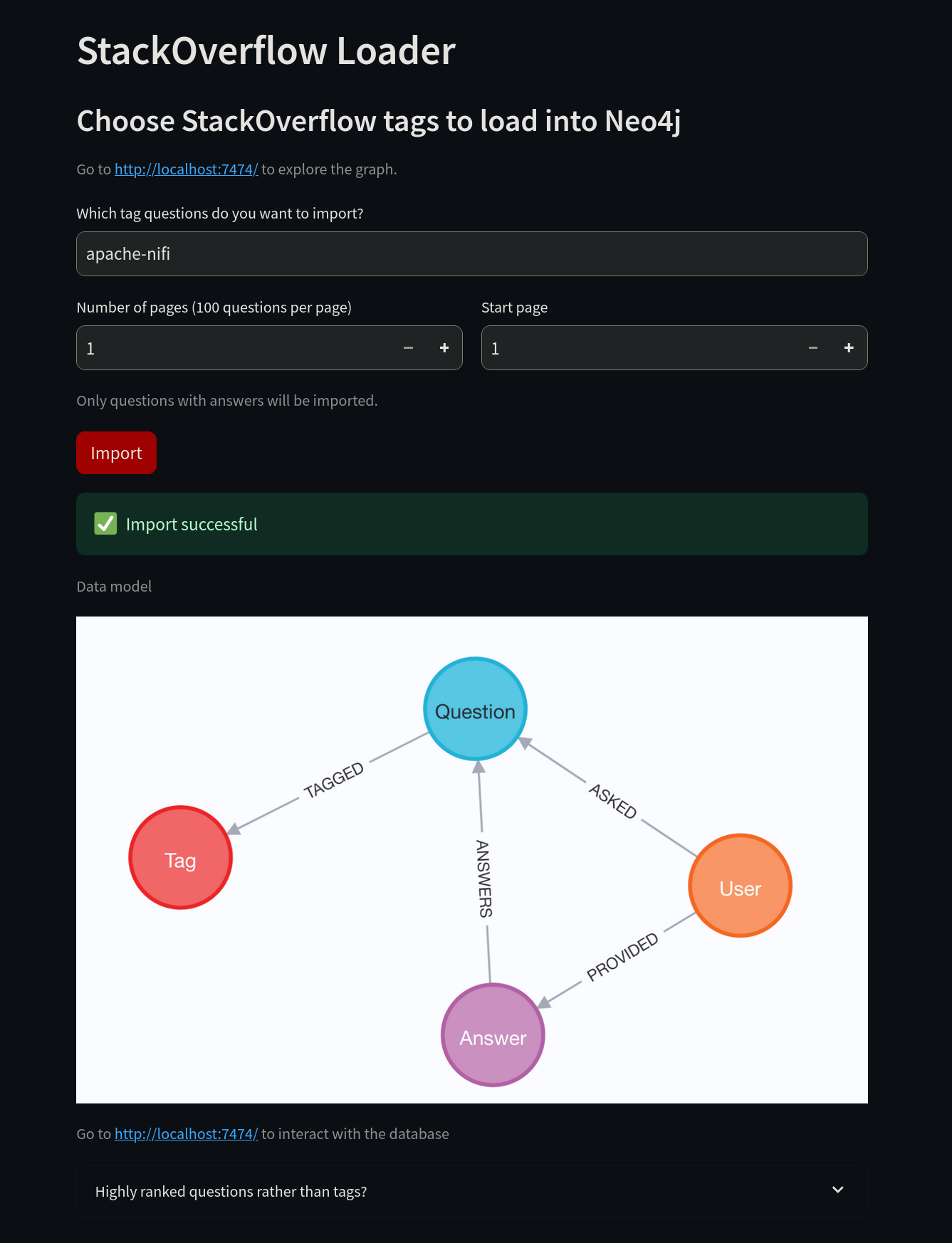
导入成功后,我们可以访问 Neo4j 来验证数据。
登录到 http://localhost:7474/ 后,使用 .env 文件中的凭据,您可以在 Neo4j 上运行查询。使用 Neo4j Cypher 查询语言,您可以检查存储在数据库中的数据。
要统计数据,请运行以下查询:
MATCH (n)
RETURN DISTINCT labels(n) AS NodeTypes, count(*) AS Count
ORDER BY Count DESC;要执行此查询,请在顶部的框中写入并选择蓝色的运行按钮。

结果将显示在下方。我们在这里看到的是系统从 Stack Overflow 下载并保存在图数据库中的信息系统。RAG 将利用这些信息来增强其响应。
您还可以运行以下查询来可视化数据:
CALL db.schema.visualization()要检查数据库中的关系,请运行以下查询:
CALL db.relationshipTypes()现在,我们已准备好让 LLM 使用这些信息。回到 http://localhost:8501/,启用 RAG 复选框,然后再次询问相同的问题。LLM 现在将提供更详细的答案。
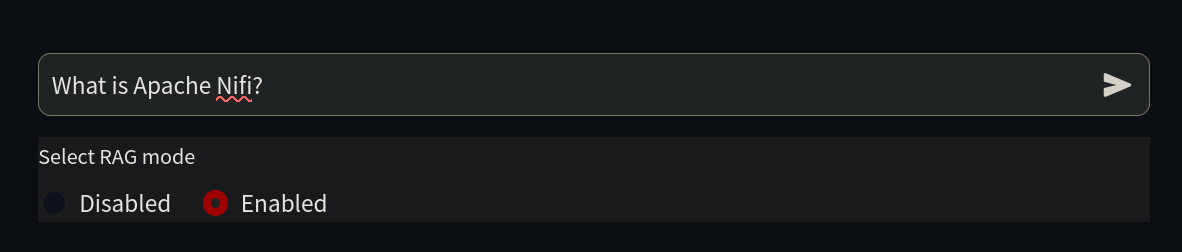
系统通过从当前技术文档中提取信息来提供全面、准确的信息。
问题:什么是 Apache Nifi?
RAG:已启用
答案:
Apache NiFi 是一个开源、分布式的数据处理系统,允许您从各种源和接收器收集、转换和传输数据。它提供了一个图形用户界面来设计和管理数据流,以及一组用于与其他系统集成的 API。
根据这个 Stack Overflow 问题,免费的 Neo4J JDBC 驱动程序不理解 SQL,只理解 Cypher,所以您需要使用非免费的 BI Connector 来从 Apache Drill 连接到 Neo4j。
此外,这个 Stack Overflow 问题表明 Apache POI 在 Neo4j 用户自定义函数中确实可以工作。但是,在初始问题中提到的独立 UDF 中可能存在未知的故障。
要使用 APOC Extended 程序将数据从 Neo4j 导出到 Excel,您可以使用 apoc.export.xls.query,它接受一个 Cypher 查询并将结果导出到 Excel 文件。
参考:
How to connect and query Neo4j Database on Apache Drill?
Is a Neo4j UDF compatible with Apache POI?请记住,Stack Overflow 上会添加新问题,由于大多数 AI 模型的固有随机性,答案可能会有所不同,不会与此示例中的完全相同。
您可以使用另一个 Stack Overflow 标签 重新开始。要在 Neo4j 中删除所有数据,您可以在 Neo4j Web UI 中使用以下命令:
MATCH (n)
DETACH DELETE n;为了获得最佳结果,请选择 LLM 不熟悉的标签。
何时利用 RAG 以获得最佳效果
检索增强生成(RAG)在标准大语言模型(LLM)不足的场景中特别有效。RAG 在三个关键领域表现出色:知识限制、业务需求和成本效率。下面,我们将更详细地探讨这些方面。
克服知识限制
LLM 在某个时间点之前基于固定数据集进行训练。这意味着它们无法访问:
- 实时信息:LLM 不会持续更新其知识,因此它们可能不知道最近的事件、新发布的研究或新兴技术。
- 专业知识:许多专业主题、专有框架或行业特定的最佳实践可能未在模型的训练语料库中得到充分记录。
- 准确的上下文理解:LLM 可能在处理频繁变化的动态领域(如金融、网络安全或医学研究)中的细微差别或不断发展的术语时遇到困难。
通过将 RAG 与 Neo4j 等图数据库结合,AI 模型可以在生成响应之前访问和检索最新、相关且高度连接的数据。这确保了答案是最新的,并基于事实信息而非推断的近似值。
解决业务和合规需求
医疗、法律服务和金融分析等行业的组织需要其 AI 驱动的解决方案具备:
- 准确性:企业需要 AI 生成的内容在其特定领域内是事实和相关的。
- 合规性:许多行业必须遵守有关数据使用和安全的严格法规。
- 可追溯性:企业通常要求 AI 响应是可审计的,这意味着它们需要引用源材料。
通过使用 RAG,AI 生成的答案可以从可信数据库中获取,确保更高的准确性和符合行业标准。这降低了诸如错误信息或违规等风险。
提高成本效率和性能
训练和微调大型 AI 模型可能计算成本高昂且耗时。然而,集成 RAG 可以提供:
- 减少微调需求:不必在新数据出现时重新训练 AI 模型,RAG 允许模型动态获取和合并新信息。
- 小模型的更好性能:通过正确的检索技术,即使是紧凑的 AI 模型也可以通过高效利用外部知识表现良好。
- 降低运营成本:不必投资昂贵的基础设施来支持大规模重新训练,企业可以通过利用 RAG 的实时检索能力来优化资源。
通过遵循本指南,您现在具备了使用 Neo4j 实现 RAG 的基础知识,使您的 AI 系统能够提供更准确、相关和有见地的响应。下一步是实验——选择一个数据集,配置您的栈,并开始通过检索增强生成的力量增强您的 AI。