使用 Kafka 和 Docker 开发事件驱动型应用程序
随着微服务的兴起,事件驱动架构变得越来越流行。 Apache Kafka 是一个分布式事件流平台,通常是这些架构的核心。不幸的是,为开发环境搭建和部署自己的 Kafka 实例通常很棘手。幸运的是,Docker 和容器让这一切变得容易得多。
在本指南中,您将学习如何:
- 使用 Docker 启动 Kafka 集群
- 将非容器化应用连接到集群
- 将容器化应用连接到集群
- 部署 Kafka-UI 以辅助故障排除和调试
先决条件
要跟随本操作指南学习,需要满足以下先决条件:
- Docker Desktop
- Node.js 和 yarn
- Kafka 和 Docker 的基础知识
启动 Kafka
从 Kafka 3.3 版本开始,由于 KRaft (Kafka Raft) 的引入,Kafka 不再需要 Zookeeper,这极大地简化了部署。借助 KRaft,为本地开发搭建 Kafka 实例变得容易得多。从 Kafka 3.8 版本开始,提供了一个新的 kafka-native Docker 镜像,它启动速度显著更快,内存占用更低。
Tip本指南将使用 apache/kafka 镜像,因为它包含许多用于管理和操作 Kafka 的有用脚本。但是,您可能希望使用 apache/kafka-native 镜像,因为它启动更快且需要的资源更少。
启动 Kafka
通过以下步骤启动一个基本的 Kafka 集群。此示例将启动一个集群,并将端口 9092 暴露给主机,以便原生运行的应用程序可以连接到它。
-
运行以下命令启动 Kafka 容器:
$ docker run -d --name=kafka -p 9092:9092 apache/kafka -
镜像拉取完成后,您将在一两秒内拥有一个正在运行的 Kafka 实例。
-
apache/kafka 镜像在
/opt/kafka/bin目录中附带了几个有用的脚本。运行以下命令以验证集群是否已启动并运行,并获取其集群 ID:$ docker exec -ti kafka /opt/kafka/bin/kafka-cluster.sh cluster-id --bootstrap-server :9092执行后将产生类似于以下内容的输出:
Cluster ID: 5L6g3nShT-eMCtK--X86sw -
创建一个示例主题并发布几条消息,运行以下命令:
$ docker exec -ti kafka /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server :9092 --topic demo运行后,您可以每行输入一条消息。例如,输入几条消息,每行一条。一些示例可能是:
First message和
Second message按
enter发送最后一条消息,完成后按ctrl+c。消息将被发布到 Kafka。 -
通过消费消息来确认消息已发布到集群:
$ docker exec -ti kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server :9092 --topic demo --from-beginning然后您应该在输出中看到您的消息:
First message Second message如果您愿意,可以打开另一个终端发布更多消息,并在消费者中看到它们出现。
完成后,按
ctrl+c停止消费消息。
您现在拥有一个本地运行的 Kafka 集群,并已验证可以连接到它。
从未容器化的应用连接到 Kafka
既然您已经证明可以从命令行连接到 Kafka 实例,现在是时候从应用程序连接到集群了。在这个例子中,您将使用一个简单的 Node 项目,它使用 KafkaJS 库。
由于集群在本地运行并在端口 9092 上暴露,应用程序可以连接到 localhost:9092 的集群(因为它现在是原生运行的,而不是在容器中)。连接后,此示例应用程序将记录它从 demo 主题消费的消息。此外,当它在开发模式下运行时,如果找不到该主题,它还会创建该主题。
-
如果您没有从前一步骤运行 Kafka 集群,请运行以下命令启动 Kafka 实例:
$ docker run -d --name=kafka -p 9092:9092 apache/kafka -
在本地克隆 GitHub 仓库。
$ git clone https://github.com/dockersamples/kafka-development-node.git -
进入项目目录。
cd kafka-development-node/app -
使用 yarn 安装依赖项。
$ yarn install -
使用
yarn dev启动应用程序。这将把NODE_ENV环境变量设置为development,并使用nodemon来监视文件更改。$ yarn dev -
应用程序现在正在运行,它将把接收到的消息记录到控制台。在一个新的终端中,使用以下命令发布几条消息:
$ docker exec -ti kafka /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server :9092 --topic demo然后向集群发送一条消息:
Test message记得在完成后按
ctrl+c以停止生产消息。
从容器和原生应用连接到 Kafka
现在您有一个应用程序通过其暴露的端口连接到 Kafka,是时候探索从另一个容器连接到 Kafka 需要哪些更改了。为此,您现在将把应用程序作为容器运行,而不是原生运行。
但在这样做之前,了解 Kafka 监听器如何工作以及这些监听器如何帮助客户端连接非常重要。
了解 Kafka 监听器
当客户端连接到 Kafka 集群时,它实际上是连接到一个“broker”(代理)。虽然代理有许多角色,但其中之一是支持客户端的负载均衡。当客户端连接时,代理会返回一组连接 URL,客户端随后应使用这些 URL 进行消息的生产或消费。这些连接 URL 是如何配置的呢?
每个 Kafka 实例都有一组监听器(listeners)和广告监听器(advertised listeners)。“listeners”是 Kafka 绑定的对象,而“advertised listeners”配置客户端应如何连接到集群。客户端收到的连接 URL 基于客户端连接到哪个监听器。
定义监听器
为了帮助理解这一点,让我们看看如何配置 Kafka 以支持两种连接机会:
- 主机连接(通过主机映射端口进入的连接)——这些需要使用 localhost 连接
- Docker 连接(来自 Docker 网络内部的连接)——这些不能使用 localhost 连接,而必须使用 Kafka 服务的网络别名(或 DNS 地址)连接
由于客户端需要通过两种不同的方法连接,因此需要两种不同的监听器——HOST 和 DOCKER。HOST 监听器将告诉客户端使用 localhost:9092 进行连接,而 DOCKER 监听器将通知客户端使用 kafka:9093 进行连接。请注意,这意味着 Kafka 正在监听端口 9092 和 9093。但是,只有主机监听器需要向主机暴露。
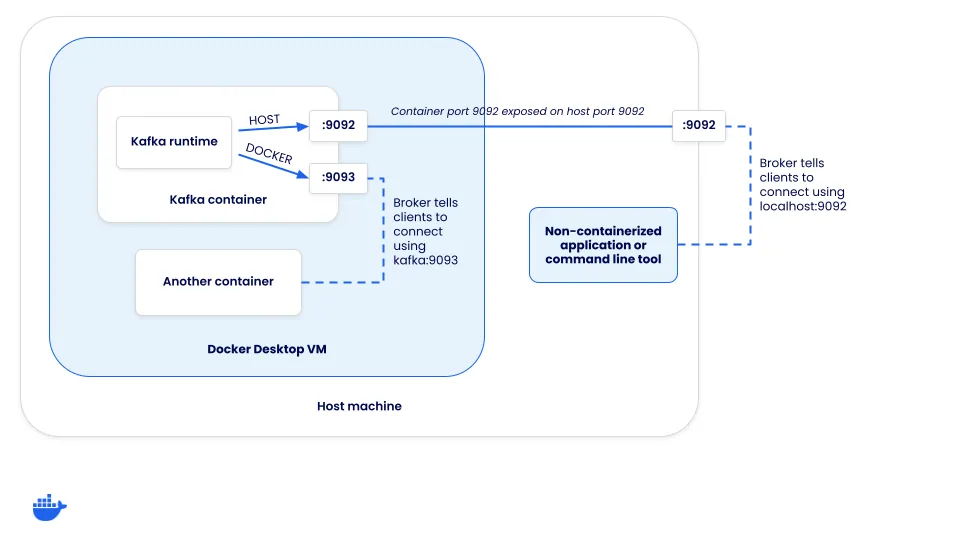
为了进行设置,Kafka 的 compose.yaml 需要一些额外的配置。一旦开始覆盖一些默认值,您还需要指定一些其他选项才能使 KRaft 模式正常工作。
services:
kafka:
image: apache/kafka-native
ports:
- "9092:9092"
environment:
# 为 docker 和主机通信配置监听器
KAFKA_LISTENERS: CONTROLLER://localhost:9091,HOST://0.0.0.0:9092,DOCKER://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: HOST://localhost:9092,DOCKER://kafka:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,DOCKER:PLAINTEXT,HOST:PLAINTEXT
# KRaft 模式所需的设置
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9091
# 用于代理间通信的监听器
KAFKA_INTER_BROKER_LISTENER_NAME: DOCKER
# 单节点集群所需
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1请按照以下步骤尝试一下。
-
如果您正在运行上一步中的 Node 应用,请在终端中按
ctrl+c停止它。 -
如果您正在运行上一节中的 Kafka 集群,请使用以下命令停止该容器:
$ docker rm -f kafka -
在克隆的项目目录的根目录下运行以下命令启动 Compose 堆栈:
$ docker compose up片刻之后,应用程序将启动并运行。
-
堆栈中包含另一个可用于发布消息的服务。通过访问 http://localhost:3000 打开它。当您输入消息并提交表单时,您应该会看到应用程序接收到该消息的日志记录。
这有助于演示容器化方法如何轻松添加额外的服务来帮助测试和调试您的应用程序。
添加集群可视化
一旦开始在开发环境中使用容器,您就会意识到添加专门用于帮助开发的其他服务是多么容易,例如可视化工具和其他支持服务。既然您正在运行 Kafka,可视化 Kafka 集群中发生的情况可能会很有帮助。为此,您可以运行 Kafbat UI web 应用程序。
要将其添加到您自己的项目中(它已经在演示应用程序中),您只需要在 Compose 文件中添加以下配置:
services:
kafka-ui:
image: kafbat/kafka-ui:main
ports:
- 8080:8080
environment:
DYNAMIC_CONFIG_ENABLED: "true"
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9093
depends_on:
- kafka然后,一旦 Compose 堆栈启动,您就可以打开浏览器访问 http://localhost:8080,并浏览查看有关集群的其他详细信息、检查消费者、发布测试消息等等。
使用 Kafka 进行测试
如果您有兴趣了解如何轻松地将 Kafka 集成到您的集成测试中,请查看 使用 Testcontainers 测试 Spring Boot Kafka 监听器指南。本指南将教您如何使用 Testcontainers 在测试中管理 Kafka 容器的生命周期。
结论
通过使用 Docker,您可以简化使用 Kafka 开发和测试事件驱动应用程序的过程。容器简化了设置和部署开发所需的各种服务的过程。一旦它们在 Compose 中定义,团队中的每个人都可以从易用性中受益。
如果您之前错过了,所有示例应用程序代码都可以在 dockersamples/kafka-development-node 中找到。